anYnt
Anytime Universal
Intelligence
Project Summary
(March 2009)
MOTIVATION
One of the most debated issues in the field of
artificial intelligence, cognitive science, psychometrics, biology and
anthropology is the definition of intelligence and its measurement.
Measurement of human intelligence is of utmost
relevance for many application areas. Consequently, psychometric tests are
common in order to (i) help children and students learn efficiently
(education), (ii) to assess personnel (selection and recruitment) and also (iii)
when treating different diseases and learning problems (learning therapies).
In a quite similar way, measurements of machine
intelligence are required for areas such as (i) making agents, robots, and
other kinds of “intelligent systems” acquire knowledge quickly (knowledge
acquisition), (ii) in order to select/assess the abilities of “intelligent
systems” (accreditation/certification) and also (iii) when trying to fix or
improve the capabilities of these systems (intelligent system design or
amendment).
Although the terminology is different, the
similarities of both areas are clear. Additionally, a third germane area is
comparative psychology or comparative cognition for several kinds of animals,
where there is also a debate about how to assess cognitive abilities in higher
animals (especially great apes and cetaceans).
The case of machine intelligence is especially
relevant because of several issues:
- A science or technology cannot advance if we do not
have proper measurement techniques to assess its progress. It is difficult to
develop aeronautics even from watching birds fly if we do not have measurements
for weight, altitude or aerodynamics. Artificial Intelligence has a reference
(Homo sapiens) but suffers a lack of measures and measurement techniques for
its artifacts.
- The ubiquity of bots, assistants, majordomos and other
kinds of autonomous agents who perform tasks on behalf of humans, makes it
difficult to appropriately deal with them in a new space for collaboration
where virtual interaction substitutes physical interaction, such as
collaborative platforms, social networks, service-oriented architectures,
e-bureaucracy, Web 2.0, etc. In many applications we need to differentiate
between stupid single-task bots, general and more intelligent bots, and humans.
o On the one hand, some applications require allowing
bots to participate in projects or granting them permissions as interlocutors
for management, negotiations or agreements. Therefore, bots are expected to be
effective to carry on their delegated tasks, for which they need to be
intelligent (non-intelligent bots are to be avoided)
o On the other hand, in some cases, we want to prevent
bots of all kinds from doing certain tasks (e.g. malicious bots could create
millions of accounts in a free email service). For this purpose, CAPTCHAs
[von Ahn et al 2002] [von Ahn et al 2008] are widely used, but more
precise and reliable mechanisms will be needed in the near-future.
Let us give an example. Imagine a collaborative
environment, where several agents (some of them humans and some of them
machines), have to build a specialized website with information about a
specific topic (e.g. a Wikipedia entry, a European project outline, a recent
event, a music library, a geographical project, etc). The team will have to
decide the rules of interaction (how information is accepted, integrated and
published). In order to become part of the team, each component will need to certify
that she/he/it has some basic reasoning/learning abilities. If an inept agent
(or person) tries to join the club we would require some kind of assessment to
decide whether we should let him/her/it in.
Are mechanisms like this available nowadays? The
answer is no. Apart from CAPTCHAs, which only measure some very specific
abilities, we do not have any kind of test where we can quickly and reliably
evaluate the intelligence of an intelligent system (an agent).
The purpose of this project is to explore the
possibility of constructing tests which are:
·
Universal. They can be applied to humans, bots, animals,
communities or even hybrids. In order to meet this property the test must be
derived from universal non-anthropomorphic principles grounded on computer
science and information theory. This goal, by itself, is very challenging since
actual tests are based on anthropomorphic assumptions.
·
Anytime. They can adapt to the time-scale of the examinee,
and can dynamically adapt its questions, interactions or items to the examinee,
in order to assess its intelligence quicker. The test should be flexible enough
to test very quickly (with low reliability) for some applications (e.g.
applications where CAPTCHAs are used today) or to provide high reliability
estimations if more time is provided (e.g. applications in which serious
consequences derive from a stupid agent meddling around).
STATE OF THE ART
There are two kinds of tests that are of interest in
this area: psychometric tests and machine intelligence tests.
Psychometric tests [Martínez-Arias et al 2006] have a
long history [Spearman 1908], they are effective, easy to administer, fast and
quite stable when used on the same individual across time. In fact, they have
provided one of the best practical definitions of intelligence: “intelligence
is what is measured by intelligence tests”. However, psychometric tests are
anthropomorphic; they cannot evaluate the intelligence of systems other than
Homo sapiens.
New approaches in psychometrics such as Item Response
Theory (IRT) allows for item selection based on their cognitive demand
features, providing results to understand what is being measured and adapting
the test to the level of the individual being examined. Items generated from
cognitive theory and analysed from IRT are a promising tool, but these models
are not fully implemented in testing [Embretson & Mc Collam 2000].
Even though these and other efforts have tried to
establish “a priori” what an intelligence test should be (e.g. [Embretson 1998]
and then find adaptations for different kinds of subjects, in general we need
different versions of the psychometric tests to evaluate children at different
ages, since the psychometric tests for adult Homo sapiens rely on some knowledge
and skills that children have not acquired yet.
The same happens for other animals. Comparative
psychologists and other scientists in the area of comparative cognition usually
devise specific tests for different species. An example of these specialised
tests for children and apes can be found here [Herrmann
et al 2007]. Additionally, it has been shown that psychometric tests do
not work for machines at the current stage of progress in artificial
intelligence [Sanghi and Dowe 2003], since they can be tricked by very simple
computer programs. But the main drawback of psychometric tests to evaluate
other subjects different from humans is that there is no mathematical
definition behind them. Hence it is difficult to devise a test which will work
on any intelligent subject (machine, human, animal ..), and not only on the
specific kind of subjects we have experimentally evaluated that they work on.
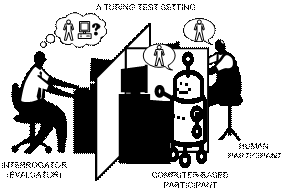
Machine intelligence tests have been proposed since
Alan Turing [Turing 1950] introduced the imitation game in 1950, now commonly
known as Turing test. In this test, a system is considered intelligent if it is
able to imitate a human (i.e., to be undistinguishable from a human) during a
period of time and subject to a (tele-text) dialogue with one or more judges.
Although still accepted as a reference to eventually check whether artificial
intelligence will reach the intelligence of humans, it has generated debates
all along. Of course, many variants and alternatives have been suggested. The
Turing test and related ideas present several problems as a machine
intelligence test: the Turing Test is anthropomorphic (it measures humanity,
not intelligence), it is not gradual (it does not give a score), it is not
practical (it is becoming easy to cheat and requires a long time to get
reliable assessments) and it requires a human judge.
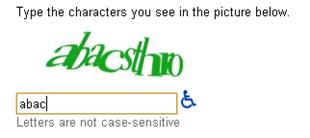
A recent and naïve approximation to a machine
intelligence test is what is called CAPTCHAs (Completely Automated Public
Turing test to tell Computers and Humans Apart) [von Ahn et al 2002] [von Ahn
et al 2008]. CAPTCHAs are any kind of simple question that can be easily
answered by a human but not by current artificial intelligence technology.
Typical CAPTCHAs are character recognition problems where letters appear
distorted. These distortions make it difficult for machines (bots) to recognize
the letters. An example of CAPTCHA from Gmail can be seen below:
The immediate objective of a CAPTCHA is to tell humans
and machines apart. The ultimate goal is to prevent bots and other kind of
machine agents or programs from being able to create thousands of accounts (or
other tasks that only humans should do). Note that bots could block or spoil
many Internet services we use as a daily basis if these and other control
techniques did not exist.
The problem of CAPTCHAs is that they are becoming more
and more difficult for humans, since bots are being specialized and improved to
read them. Whenever a new CAPTCHA technique is developed, new bots appear that
have chances of getting through the test[1]. This forces CAPTCHA developers to change
them again, and so on and so forth. The reason is that they are specific and
they rely on some particular tasks. Although CAPTCHAs work reasonably well
today, in about 10 or 20 years, they will need to make things so difficult and
general, that humans will require more time and several attempts to make it
through. In fact, this is already happening, and we lose more and more time in
CAPTCHAs everyday.
Apart from tests, a much more theoretical and formal
approach to machine intelligence has been undertaken by prominent scientists in
the 20th century such as A.M. Turing, R.J. Solomonoff, E.M. Gold, C.S. Wallace,
J.J. Rissanen, L. Blum and M. Blum, G.J. Chaitin and others. The landmark is the
development of Algorithmic Information Theory (also known as Kolmogorov
Complexity) (see [Li & Vitányi 2008] for the most complete reference on
it), its relation to learning (inductive inference and prediction) [Solomonoff
1964] [Wallace and Boulton 1968] [Solomonoff 1986] [Wallace and Dowe 1999]
[Wallace 2005] and ultimately its relation to intelligence.
These ideas led to some members of the team who are
now presenting this project hereby to introduce some formal definitions of
intelligence, namely the works [Dowe & Hajek 1997, 1998] [Hernandez-Orallo
& Minaya-Collado 1998] [Hernandez-Orallo 2000a] [Hernandez-Orallo 2000b].
All of these tests and definitions are mathematical, non-anthropomorphic (i.e.
universal), meaningful and intuitive. In this sense they do not take Homo
Sapiens as a reference and judge (as in the Turing Test), they have not evolved
by trial and error through experimentation on testing subjects during a century
(such as generally done in psychometrics) but they are constructed over fundamental
and mathematical notions in computation theory. And some of them succeeded to
be practical (feasible as an intelligence test) at the cost of being partial
(in the sense they measure necessary traits of intelligence but not all of
them). Let us see these approaches in more detail below:
On the one hand, Dowe & Hajek [Dowe & Hajek
1997, 1998] suggested the introduction of induction inference problems in a
somehow induction-enhanced or compression-enhanced Turing Test,
in order to, among other things, deal with Searle’s "Chinese room"
paradox, and also because an inductive inference ability is a necessary (though
possibly "not sufficient") requirement for intelligence.
On the other hand, quite simultaneously and similarly,
and also independently, in [Hernandez-Orallo & Minaya-Collado 1998]
[Hernandez-Orallo 2000a], intelligence was defined as the ability to
comprehend, giving a formal definition of the notion of comprehension as the
identification of a ‘predominant’ pattern from a given evidence, derived from
Solomonoff induction and prediction concepts, Kolmogorov complexity and Levin’s
variants and optimal search. The definition was given as the result of a test,
called C-test [Hernandez-Orallo & Minaya-Collado 1998], formed by
computationally-obtained series of increasing complexity. The sequences were
formatted and presented in a quite similar way to psychometric tests, and as a
result, the test was administered to humans. Nonetheless, the main goal was
that the test could eventually be administered to other kinds of intelligent
systems as well.
A factorisation (and hence extension) of these
inductive inference tests was sketched in order to explore which other
abilities could conform a complete (and hence sufficient) test
[Hernandez-Orallo 2000b]. In order to apply the test for low intelligent
systems, (still) unable to understand natural language, the proposal for a
dynamic extension of the C-test in [Hernandez-Orallo 2000a], was expressed like
this: “the presentation of the test must change slightly. The exercises should
be given one by one and, after each guess, the subject must be given the
correct answer (rewards and penalties could be used instead)”.
Recent works by Legg and Hutter (e.g. [Legg and Hutter
2007]) have followed the previous steps and, strongly influenced by Hutter’s
theory of AIXI optimal agents [Hutter 2005], have given another (and related)
definition of machine intelligence, dubbed “Universal Intelligence”, also
grounded in Kolmogorov complexity and Solomonoff's induction.
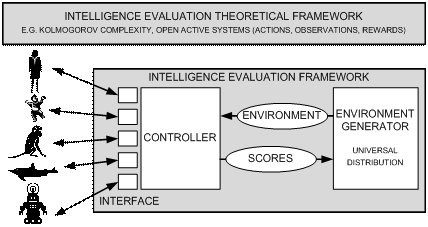
The basic idea is to evaluate the intelligence of an
agent p on several environments m, chosen by using the universal
distribution[2] (the one derived from Kolmogorov Complexity,
i.e, p(m)= 2-K(m)), using rewards that are accumulated during the
interaction with the environment. So intelligence is defined as the competence
of an agent in different environments, where simple environments have more
probability than complex environments.
The comparison with the works from Hernandez-Orallo
(but also Dowe & Hajek's compression test) is summarised by [Legg and
Hutter 2007] with the following table:
|
|
Universal agent |
Universal test |
|
Passive environment |
Solomonoff induction[3] |
C-test |
|
Active environment |
AIXI |
Universal intelligence |
In fact, the definition based on the C-test can be
considered an instance of Legg and Hutter’s work, where the environment outputs
no rewards, the agent is not allowed to make an action until a number of
observations is seen (the inductive inference sequence). In our opinion, one of
the most relevant contributions in their work is that their definition of
Universal Intelligence allows one to formally evaluate the theoretical
performance of some agents: a random agent, a specialised agent, ..., or a
super-intelligent agent, such as AIXI [Hutter 2005], which is claimed to be the
agent that, if ever constructed, would score the best in the Universal
Intelligent test. In a nutshell, Legg and Hutter's work is another step that
helps to shape the things that should be addressed in the near future in order
to eventually reach a theory of machine intelligence.
There are, however, five problems we have identified
in their definition with regard to making it practical. First, we have an
infinite sum over all the environments. Secondly, we also have an infinite sum
over all the possible rewards (agent's life in each environment is infinite).
Third, K() is not computable. Fourth, and more importantly, time is not taken
into account. And, fifth, there is a conflation between induction and
prediction.
PROPOSAL
In this work we propose a modification and extension
of the previous definitions and tests in order to construct the first general,
necessary, formal, feasible intelligence definition and test. The definition
and test will be grounded on previous developments on tests based on Kolmogorov
Complexity [Dowe & Hajek 1997, 1998] [Hernandez-Orallo & Minaya-Collado
1998] [Hernandez-Orallo 2000a, 2000b] [Legg and Hutter 2007]). The main idea of
all of them is that the Universal Distribution is used for the
generation of questions and environments, and hence any particular bias towards
a specific individual, species or culture is avoided. This makes the test
universal for any possible kind of subject. But apart from this “Universal”
condition we will focus on some additional practical requirements:
-
It must allow one to measure any kind of
intelligent system (biological or computational) which exists now or can be
built in the future (anytime systems).
-
The test must quickly adapt to the level
of intelligence and time scale of the system. It must be able to evaluate inept
and brilliant systems (any intelligence level) as well as very slow to
very fast systems (any time scale).
-
The quality of the assessment will depend
on the time we leave for the test. That means that the test can be interrupted
at any time, producing an approximation to the intelligent score. The more time
we leave for the test, the better the assessment (anytime test).
Because of these requirements we will call the tests
"anytime universal intelligence tests". If we succeed, science
will be able to measure intelligence of higher animals (e.g. apes), humans,
machines, hybrids or communities of humans and machines and, eventually,
extraterrestrial beings in an absolute way.
The main difficulty to make it feasible is that the
more general we intend the test to be, the fewer things about the agent should
be assumed. That means that we may require more time to evaluate intelligence,
because we can neither rely on a common knowledge nor language to explain the
instructions or give things for granted. The problem is similar to evaluating
children or animals, where everything must be quite symbolic and simple, and
subjects must be led toward a goal through rewards and penalties. That is the
reason why these tests are more interactive than traditional psychometric tests
for adult Homo sapiens.
In fact, there is a common thesis in all intelligence
tests (both from psychometrics, comparative cognition or artificial
intelligence): the time which is required to evaluate the intelligence of a
subject depends (1) on the knowledge or features which are expected and known
about the subject (same species, same culture, same language, etc.) and (2) on
the adaptability of the examiner. While (1) is taken to the extreme in
human psychometrics, where tests are just a form with questions explained in
natural language, (2) is taken to the extreme with the Turing Test or any kind
of interview evaluation, where the examiners are humans who dynamically adapt
their questions according to the subject’s answers.
Consequently, if we want to evaluate different kinds
of subjects without relying on any assumption about their nature or knowledge,
and if we want to get a reliable assessment in a reduced (practical) period of
time, .we must necessarily devise interactive and adaptive tests,
Although the endeavour looks pretentious and bold,
there are some facts and some reasonable hypotheses which give strong support,
at least, in considering the effort of attempting a first prototype of this
test and a preliminary evaluation in order to establish whether these tests are
constructible.
Facts:
- Works in [Hernandez-Orallo & Minaya-Collado
1998] [Hernandez-Orallo 2000a] showed that static tests derived from
Kolmogorov Complexity are useful to evaluate Homo sapiens and they correlate
with classical IQ tests. Additionally, problems with higher Kolmogorov
Complexity have also been shown to be more difficult for Homo sapiens than
problems with lower complexity, so meaning that the Universal Distribution
is correlated with the notion of difficulty.
- CAPTCHAs have had a strong impact in real
applications (almost every collaborative or Web 2.0 platform has one), and
also in the scientific community, with featured articles in the most
important general scientific journal (Science) and the most important
general computer science journal (Communications of the ACM). Despite its
big impact, It is widely recognised that CAPTCHAs will have to be
substituted by something more elaborate in the future.
- Some works in psychometrics about “adaptive item
generation” [Embretson 2004], have developed the idea that tests can be
constructed by using an item generator which adapts to the subject’s level
of intelligence, according to its answers. The test is not a form but an
interactive test where the subject interacts with a machine examiner
(which, by the way and not coincidentally, uses techniques from artificial
intelligence to adapt to the examinee).
- [Legg and Hutter 2007] shows that the previous
static tests can be converted into dynamic tests through the idea of
"environments" and "rewards". In fact, Legg received
the “Singularity Institute for Artificial Intelligence Canada
Academic Prize for 2008” for this work.
- There are computable variants of Kolmogorov
Complexity (e.g. Levin's Kt) [Levin 73] [Li & Vitányi 2008]. In fact,
this variant is used in [Hernandez-Orallo 2000a].
Hypotheses:
§
We can only assume a few things about
the subject to be examined. It will be an open active system that will have
some sensors and some actuators, and, additionally, there will be a way to
conduct its behaviour through rewards and penalties. All the subjects we
contemplate (humans, animals, reactive machines with rewards) accomplish this[4],
and we think there is no need to assume anything else about the physics,
implementation or behaviour of the subject in order to evaluate it.
§
Interacting with a sample of
environments under the universal distribution is sufficient to evaluate
general intelligence. While it seems to only measure inductive abilities, many
environments will also require memory and deductive abilities to succeed. This
does not exclude the design of factorial tests, by posing specific constraints
on the kind of environments. However, this factorisation goes out the scope of
this project.
§
A relatively small sample of
environments can be used instead of all of them, in order to make the test as
shorter as possible. The complexity of the environments can also progressively
be adjusted to match the intelligence of the agent, and their rewards weighted
accordingly, in order to make the test more effective.
§
Time can be included by allowing the
agent to play with a single environment for a fixed time. This time limit can
progressively grow to make the test anytime. Rewards might be time-dependent so
the agent can realise that time is relevant.
Finally, it may seem difficult to imagine what one of
these "anytime universal intelligence tests" might look like, but we
find similar things everywhere: games, child games, where children start with
easy ones and soon move to more sophisticated ones. To find an even closer
parallel, the anytime intelligence test may be quite similar to a random collection
of videogames where we play for a little time with the easy ones first and then
we are given more time to play with some other more difficult ones if we
succeed on the easiest one. As usual, easy levels can be passed quickly and
difficult levels require more time. The intelligence of an agent would be some
kind of average of the scores in all the levels, possibly using some kind of
log-loss measure on the complexity of each level. The key point here is that
these games or environments will be generated according to a distribution which
is independent (and hence neutral) over the different kinds of subjects
(humans, machines, animals...) to be evaluated.
ACTIVITIES
The project spans for one and a half years, starting
in July 2009. The project is divided into three stages, about six months each.
- STAGE 1: Theoretical development. In this stage,
we define how to make a sample of environments, how to change environment
complexity to adapt to agent's intelligence, how to deal with time, how to
score rewards and penalties.
- RESULT: A theoretical definition of an anytime
universal test based on Kolmogorov Complexity in a form which will be
ready for implementation. The process and justification of the test will
be written as journal/conference papers and associated technical reports.
- STAGE 2: Implementation of the test. In this
stage, we will need to choose a platform and a reference machine for which
we generate the environments from an environment language or grammar. We
must also choose an interface as neutral as possible, which might be
adaptable for different kind of subjects.
- RESULT: A publicly available implemented test,
with flexible interfaces for different kinds of subjects, interactions
and rewards.
- STAGE 3: Evaluation of the test. In this stage,
we will administer the test to humans, machines and, if possible, apes and
children. The use of machines will also require adapting existing learning
agents for the task and playing with some of their factors (speed,
learning ability, memory, etc.) in order to see how these changes affect
the intelligence score.
- RESULT: A report with a statistical analysis
providing conclusions on the feasibility of such a test and a suggestion
of possible changes in order to improve it. In case results are negative,
an analysis of possible causes or identification of possible wrong
hypotheses.
IMPACT:
In case the results of the project are successful, we
will follow up with extensive publications of the results and also will start
some other more traditional projects exploiting the results, in order to
enhance the tests, factorise them and make them publicly available for several
scientific disciplines: artificial intelligence, psychometrics, comparative
cognition, etc.
Eventually, the acceptance and use of these tests
would allow the following:
- Progress in AI would be boosted
because systems could be evaluated. Contests and competitions would foster
and would provide enormous feedback information to improve intelligent
systems.
- New generation of CAPTCHAs taking into account
some of the ideas of the tests or fast adaptation of the tests could be
developed.
- Certification tests would be devised in order to
automatically decide whether an unknown agent can be accepted for a
collaborative project. In other words, we would be able to establish
cognitive requirements in order to admit an agent in a project.
- At a long term, these tests will be necessary to
determine when we reach the “Technological Singularity” (the point in
evolution where a species is able to build a system as intelligent as
itself), which some researchers place around about twenty years from now.
This means that in about that time, we will require a battery of tests for
different degrees of intelligence and different kinds of factors, since
intelligent systems will converge sooner on some intelligent factors than
others. Additionally, a test like this will help to focus the ethical
debate that will be generated near the moment of the singularity.
In other words, and getting back to the similarities
between machine intelligence tests and psychometrics, we would expect at least
the same applications that psychometrics have today in education, recruitment
and therapy into the world of artificial intelligence, where the areas are
known as knowledge acquisition, agent cognitive certification and agent
redesign.
REFERENCES:
[Dowe and Hajek 1997] D L Dowe, A R
Hajek (1997), "A computational extension to the Turing Test",
Technical Report #97/322, Dept Computer Science, Monash University, Melbourne,
9pp, 1997. http://www.csse.monash.edu.au/publications/1997/tr-cs97-322-abs.html
[Dowe and Hajek 1998] D L Dowe and A R Hajek (1998). A
non-behavioural, computational extension to the Turing Test, pp101-106,
Proceedings of the International Conference on Computational Intelligence &
Multimedia Applications (ICCIMA'98), Gippsland, Australia, February 1998
[Embretson 1998] Embretson, S. E. (1998). A cognitive
design system approach to generating valid tests: Application to abstract
reasoning. Psychological Methods, 3, 300-396.
[Embretson
& Mc Collam 2000] Embretson, S.E. y McCollam, K.M.S. (2000). Psychometric approaches to understanding and measuring
intelligence. En R.J. Sternberg (Ed.). Handbook of intelligence (pp. 423-444).
Cambridge, UK: Cambridge University Press.
[Embretson 2004] Embretson, S.
E. 2004. Measuring human intelligence with artificial intelligence: Adaptive
item generation. In R. J. Sternberg & J. Pretz (Eds.). Cognition and
Intelligence. New York: Cambridge University Press. (http://psychology.gatech.edu/departmentinfo/faculty/bio-SEmbretson.html)
[Herrmann et al 2007] Esther Herrmann,
Josep Call, María Victoria Hernández-Lloreda, Brian Hare, Michael Tomasell
"Humans Have Evolved Specialized Skills of Social Cognition: The Cultural
Intelligence Hypothesis", Science, 7 September 2007, Vol. 317. no. 5843,
pp. 1360 - 1366, DOI: 10.1126/science.1146282
[Hernandez-Orallo
& Minaya-Collado 1998] Hernández-Orallo, José;
Minaya-Collado, N.: A Formal Definition of Intelligence Based on an
Intensional Variant of Kolmogorov Complexity, Proceedings of the
International Symposium of Engineering of Intelligent Systems (EIS'98) ICSC
Press 1998, pp. 146-163
[Hernandez-Orallo 2000a] José
Hernández-Orallo: Beyond the Turing Test. Journal of Logic, Language and Information 9(4):
447-466 (2000)
[Hernandez-Orallo 2000b]
Hernández-Orallo, José On
The Computationl Measurement of Intelligence Factors, appeared in A. Meystel Performance Metrics for Intelligent Systems Workshop, National Institute of Standards and Technology,
Gaithersburg, MD, USA, August 14-16, 2000, pp. 1-8, section XXI.]
[Hutter 2005] Hutter, M. “Universal
Artificial Intelligence: Sequential Decisions based on Algorithmic
Probability”, Springer, 2005.
[Legg
and Hutter 2007] Legg, S.; Hutter, M. Universal Intelligence: A Definition of Machine
Intelligence
Shane Legg and Marcus Hutter. In Minds
and Machines, pages 391-444, volume
17, number 4, November 2007. http://www.vetta.org/documents/UniversalIntelligence.pdf
[Legg 2008] Shane Legg. Department of Informatics, University of
Lugano, June 2008. http://www.vetta.org/documents/Machine_Super_Intelligence.pdf
[Levin
73] Levin, L.A. "Universal search problems" Problems Inform.
Transmission, 9:265-266, 1973.
[Li & Vitányi 2008] Li, Ming; Vitányi, Paul "An Introduction to Kolmogorov Complexity and its Applications" 3rd Edition. Springer-Verlag, New York, 2008.
[Martínez-Arias et al 2006] Martínez-Arias, M.Rosario; Hernández-Lloreda, M.Victoria; Hernández-Lloreda, M.José. “Psicometría”, Alianza Editorial 2006.
[Sanghi and Dowe 2003] Sanghi, P. and D.L. Dowe (2003). A computer program capable of
passing I.Q. tests, Proc. 4th International Conference on Cognitive Science
(and 7th Australasian Society for Cognitive Science Conference), ICCS ASCS 2003
(http://www.cogsci.unsw.edu.au), Univ. of NSW, Sydney, Australia, 13-17 July
2003, Vol. 2, pp. 570-575.
[Solomonoff
1964] Solomonoff, R.J. "A formal theory of inductive inference"
inform. Contr. vol. 7, pp. 1-22, Mar. 1964; also, pp. 224-254, June 1964.
[Solomonoff
1986] Solomonoff, R.J. "The Application of Algorithmic Probability to
Problems in Artificial Intelligence" in L.N.Karnal and J.F. Lemmer (eds.) Uncertainty
in Artificial Intelligence (L.N. Karnal and J.F. Lemmer, eds.), Elsevier
Science, pp. 473-491, 1986.
[Spearman 1904] Spearman, C. “ ‘General Intelligence’
objectively determined and measured” American Journal of Psychology 15,
201-293, 1904.
[Turing 1950] Turing, Alan “Computing Machinery and
Intelligence” Reprinted in “Minds and Machines”, edited by Alan Ross Anderson,
Englewood Cliffs, N.J., Prentice Hall 1964.
[von Ahn et al 2002] von Ahn, L.; Blum, M.; Langford,
J. “Telling Humans and Computers Apart (Automatically) or How Lazy
Cryptographers do AI” Communications of the ACM, 2002. www.captcha.net.
[von Ahn et al 2008] von Ahn, L.; Maurer, B.;
McMillen, C.; Blum, M. "reCAPTCHA: Human-Based Character Recognition via
Web Security Measures" Science, Vol. 321, September 12th, 2008.
[Wallace
2005] C. S. Wallace, Statistical and Inductive Inference by Minimum Message
Length, Information Science and Statistics", 432, Springer Verlag,
May,2005.
[Wallace
and Boulton 1968] Wallace, C.S. and Boulton, D. M. "An Information Measure
for Classification" Computer Journal, 11, 2, pp. 185-195, 1968.
[Wallace
and Dowe 1999] C. S. Wallace and D. L. Dowe "Minimum Message
Length and Kolmogorov Complexity", Computer Journal, 1999, vol 42, no. 4,,
pp. 270-283,
[1] For instance, JAntiCaptcha is a tool developed by JDTeam that is
included in JDownloader. It allows to crack CAPTCHAs from the most popular download
sites (e.g. MegaUpload, RapidShare).
[2] Universal
distribution is defined over a particular reference machine, but this choice
only affects Kolmogorov complexity by a constant. As such, we take the liberty
at saying "the" universal distribution.
[3] More precisely, it is really "Solomonoff prediction", but we
show it as it is in the original table.
[4] Sensors may either be eyes and
ears, or a camera and a microphone, or a communication-listening e-service,
etc. Actuators may either be hands, muzzle, fins, a robotic pincer, or an
e-service invocator software module, etc.